Article
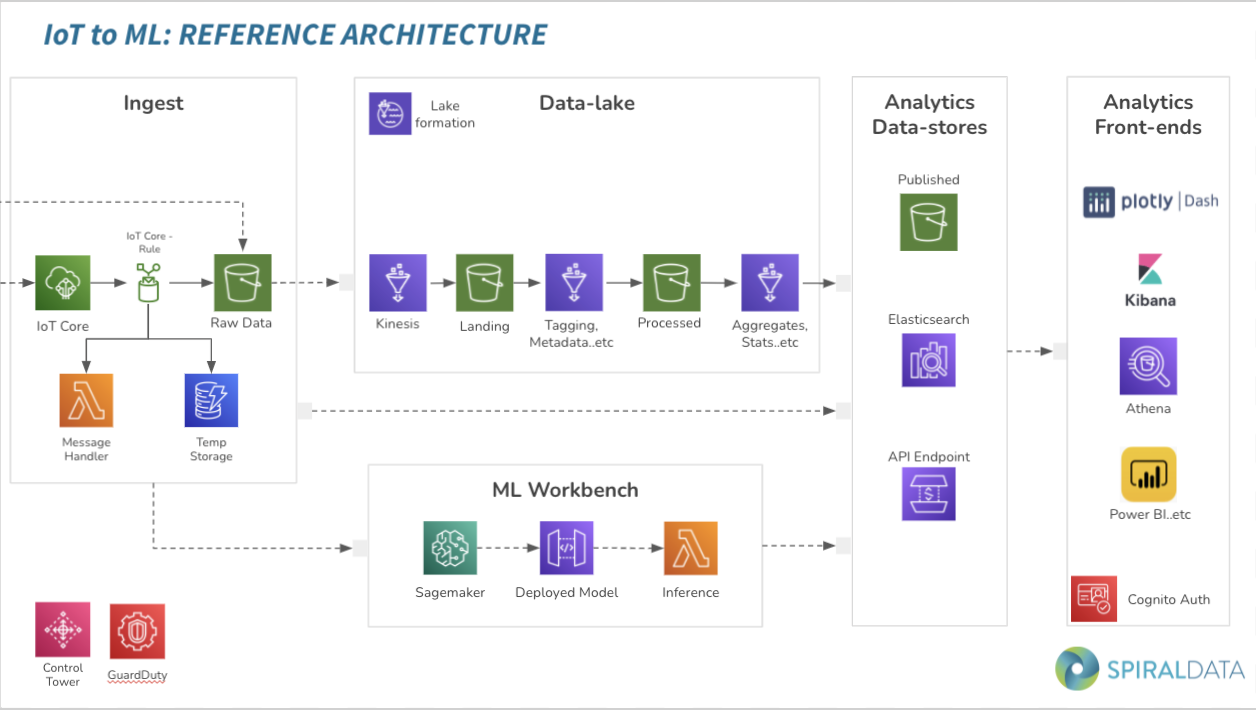
IoT-to-ML reference architecture
CTO Chris Jansz presented SpiralData’s Machine Learning Workbench at AWS meetup
SpiralData has presented “The Good, the Bad and the Architecture of Data Analytics” at the Amazon Web Services meetup in Adelaide. CEO Kale Needham and CTO Chris Jansz showcased real-time machine learning examples for predictive maintenance and SpiralData’s IoT-to-ML reference architecture.
Transcript Summary
SpiralData has been working on implementing IoT and machine learning architecture since 2017, starting off with a GPS-based solution tracking 150 vehicles. We then moved on to Google Maps, using machine learning and natural language processing for lead generation. Most recently, we worked with SAGE Automation to ingest data from a pump rig, using machine learning modules to identify blockages in pipe networks.
The architecture itself has been through a number of revisions and iterations based on real world experience. For every project that SpiralData implements, we have a retrospective of best practices and we use AWS Well-Architected Framework for continuous review.
SpiralData’s reference architecture has two key features. Firstly, it is a modular design, where customers don’t need to implement all services from day one. SpiralData runs a co-design workshop to identify the customer’s needs and requirements. We take them through a questionnaire for the architecture, security posture and UI design. The outcome of this workshop is a clear understanding of the requirements, which modules we need to implement, the security guidelines and any compliance requirements. The second feature is the Well-Architected Framework to evaluate all services used in the architecture, as well as how we implement them.
Moving on to the architecture itself, we start off with the Ingest module. The purpose of the Ingest module is to ingest any kind of data from IoT sensors, corporate systems, finance or sales systems, being able to handle hundreds of thousands of devices streaming in near real-time while keeping the cost at a manageable level. One of the services SpiralData uses is IoTco, which manages all incoming data, security, connectivity, and streaming of real-time data. We have IoTco rules, which handles where the data lands. For real-time monitoring, we send it through to Elasticsearch or S3 buckets, which we use as a raw storage device. Later on, if the customer wants to analyse data collected over the past six months, we don’t have to wait for another data set to come through. Lambda is used as an intermediate step for processing and pushing that into other destinations, while DynamoDB is used as a temporary storage for ML inference.
The second module is the data lake, a scalable solution to process, link and store huge volumes of data for the analytics. It is not limited by data source, type or structure: it could be IoT, corporate system or even a public API. We use Lake Formation to manage the security, the catalogs and the labels of the data lake. Kinesis Firehose is used as an ETL tool for processing data, and S3 is used for multi-stage data storage. We have multiple S3 buckets for published data where ad hoc analytics can be executed.
Another module is the Analytics Data Stores, which are based on customers’ requirements. When we carry out the co-design workshop, we identify which services they want to implement based on requirements, budget and timelines. For example, we can set up an S3 bucket for a very cost-effective way of analysing ad hoc data. We use Elasticsearch for real-time time series analytics and advanced search capabilities, and API Gateway for internal and external applications to access real-time data and machine learning inference.
The next module is the front end. When it comes to front-end BI tools, the options are endless. SpiralData has added a subset of services mainly focused on time series use cases. Until recently we were using Elasticsearch Kibana as the front end analytics visualisations, but it has its limitations when the customer requires a very customised dashboard. We had an internal assessment of possible solutions or tools, and we selected Plotly Dash as the default visualisation for highly customised front ends. We still use Elasticsearch Kibana, which has a real-time monitoring and alert systems into SMS, email, Slack channels, or any other solution that supports Web Books. Then Athena might be implemented if the end user wants ad hoc analytics or query, along with a quick site for dashboarding. Some of our customers have already implemented Microsoft licensing and don’t want to invest on another front end tool, so we use the API endpoint, allowing them to access Power BI. Overall, we use Cognito as the authentication service and authorisation. For customers who have Power BI, we integrate Azure Redis with Cognito.
The final module is the ML workbench. We have learned over the years that our customers want to focus on ML itself before looking into other areas, because machine learning gives them a very fast insight on issues they are having and the ability to allocate budget. With SpiralData’s module approach, we could simply implement the Ingest and the ML modules, with the client allocating a budget for future projects.
In this module we use SageMaker throughout. SageMaker is used for model training and deployment, it also provides Jupyter notebooks on the cloud, which integrates with GitHub for version control. It also provides the ability to quickly set up developer environments, without the need to install Python packages on local machines. If there is a requirement for continuous model training and deployment, the model can be set up to a scheduled retraining and redeployment according to a specific criteria. We can improve the efficiency or accuracy of some models if we have more data as we go along, training it with the extended set of data and redeploying it. The inference is connected to the API gateway, allowing for external applications to use the machine learning inference feature. At minimum, we use AWS Control Tower and GuardDuty for security governance and monitoring, but other services can be implemented depending on the customer’s security needs.
SpiralData currently uses a combination of cloud formation and automation scripts. Cloud formation sets up a certain set of services, and the automation scripts come into creating user profiles, setting up SageMaker and other configurations.
To see examples of real time machine learning for predictive maintenance in water utilities click here.
